


NIS 2, Cloud Act, DINUM : on a refondu notre modèle de cahier des charges ...
change de nom...
Lors d'un atelier pour un lieu à fort trafic, une question banale a révélé une faille stratégique : "Combien de temps un usager passe-t-il à chercher une information avant de l'abandonner ?". Personne n'avait la réponse, mais tout le monde partageait la même intuition : trop longtemps.
Entre les menus profonds, les PDF à télécharger et les formulaires rigides, l'information, bien que présente, est souvent difficile à atteindre dans un contexte où chaque minute compte. Ce n'est pas un problème de transport, mais celui de toute organisation produisant de la donnée massive : hôpitaux, impôts ou opérateurs touristiques…
La plupart des organisations veulent "faire de l'IA" pour l'image. La vraie question est opérationnelle : quel est le manque à gagner quand un usager abandonne sa recherche après 30 secondes ?
Pour répondre à cet enjeu, nous décortiquons d'abord le changement de paradigme technique nécessaire pour transformer l'IA en un véritable levier de performance, avant d'illustrer cette approche par un cas d'usage concret : la création d'une conciergerie intelligente pour un acteur majeur du transport aérien.
La première erreur est de penser “Chatbot”, on imagine qu'un assistant doit "discuter". Or l'usager ne cherche pas une relation, mais une réponse. L’enjeu, c'est de passer de 10 clics dans des menus à une seule intention comprise et L'IA ne doit pas être un interlocuteur, mais un accélérateur de résolution. Un chatbot qui reformule une FAQ est une régression de l'expérience utilisateur voire même une dette technique. Google ne vous force pas à discuter pour trouver un itinéraire; il comprend votre intention et affiche la réponse. Ils vendent de la donnée vivante, pas du temps de discussion.
Pour construire ce service, nous transformons l'accès à l'information via trois couches technologiques.
Le moteur de recherche classique (mots-clés) est limité : il gère mal les synonymes et le contexte d’une information.
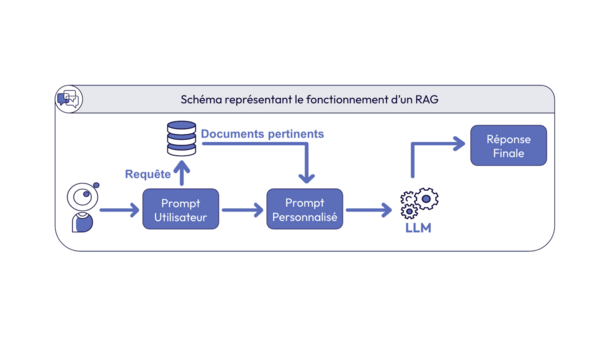
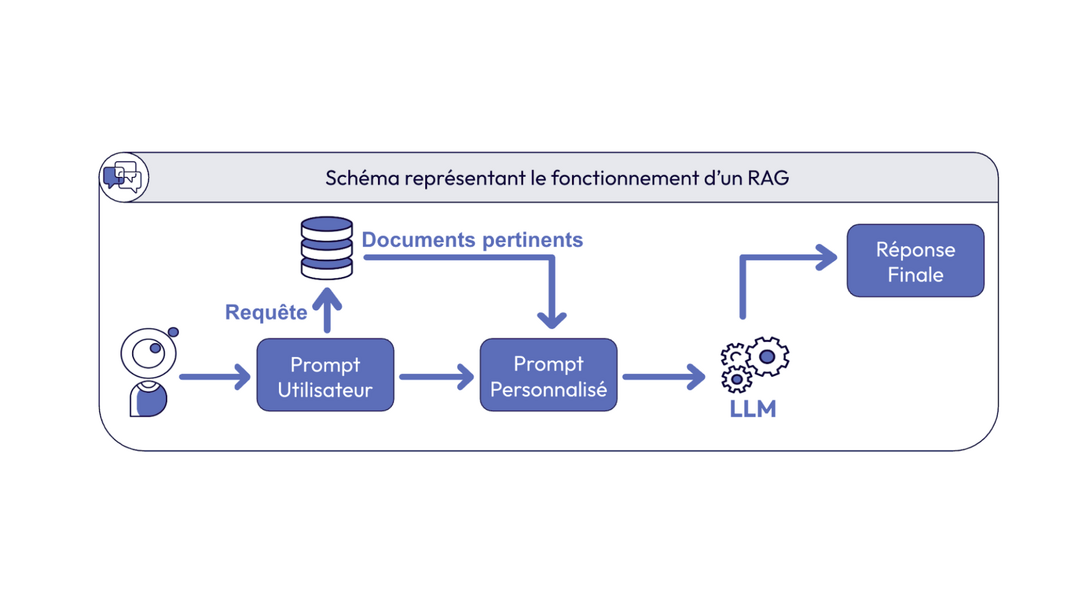
C'est là qu'intervient la recherche sémantique : au lieu de chercher des mots-clés, le système identifie les passages de vos contenus qui ont du sens par rapport à la question posée, et le LLM s'en sert pour construire une réponse précise.
En résumé : le LLM comprend la question, la recherche sémantique trouve la bonne source, et le LLM reformule. Rien d'autre.
Le piège de l'IA générative, c'est l'hallucination : inventer une réponse plausible mais fausse. Avec le RAG (Retrieval-Augmented Generation), on évite ce risqueen changeant le rôle du LLM. Il n'est plus une source d'information, il est un moteur de formulation. Il ne puise ses réponses que dans le périmètre que nous avons défini : vos sources certifiées, et rien d'autre. Si une information est absente ou périmée, l'assistant doit savoir se taire plutôt que d'improviser.
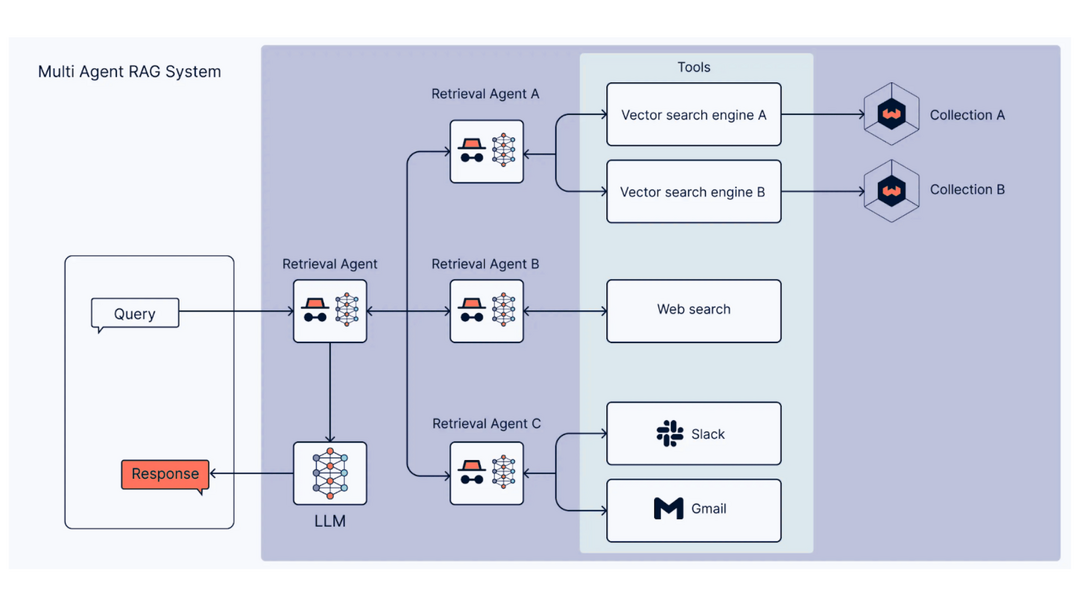
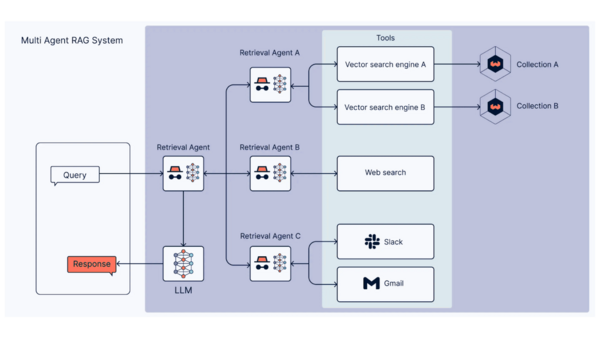
Les API classiques sont trop rigides pour les modèles de langage. Nous implémentons le Model Context Protocol (MCP), un standard qui agit comme “un traducteur de capacité”.
| Option | Gain | Perte | Angle mort |
| Moteur sémantique seul |
| Pas de langage naturel "parlé". | L'utilisateur doit encore parcourir des résultats. |
| RAG (Retrieval-Augmented Generation) | Réponses certifiées et ancrées sur vos contenus. | Dépendance aux données "froides" (PDF, textes). | Incapacité à traiter les données vivantes (flux temps réel). |
| Orchestration multi-agents via MCP |
| Complexité de développement initiale. | Nécessite des API métiers robustes. |
Cette architecture reposant sur la recherche sémantique, le RAG et le protocole MCP n'est pas qu'une vision théorique ; elle constitue le moteur d'une nouvelle génération de services. Pour comprendre comment ces briques technologiques révolutionnent concrètement l'expérience usager, plongeons dans l'analyse de notre projet de conciergerie transactionnelle.
L'idée de départ est simple : au lieu que l'usager navigue dans des menus pour trouver l'information, il pose sa question en langage naturel, comme il le ferait à un agent d'accueil et il obtient une réponse directe, précise, en quelques secondes.
Dans notre cas, les questions ressemblaient à ça :
Mais la même logique s'applique à beaucoup d'autres contextes. Un patient qui demande "Comment préparer ma consultation ?" à un centre hospitalier. Un administré qui veut savoir "Quels documents apporter pour renouveler ma carte d'identité ?" à sa mairie. Un client qui cherche "Quelle est la politique d'annulation pour mon séjour ?" sur un site hôtelier. Dans tous ces cas, l'information existe. Elle est juste inaccessible au moment où elle est nécessaire.
Des questions simples. Des réponses qui, aujourd'hui, demandent plusieurs clics, plusieurs formulaires, parfois un appel téléphonique. L'usager passe son temps à assembler des informations éparpillées alors qu'il devrait juste obtenir ce dont il a besoin.
Ce qu'on voulait construire, c'est un service de conciergerie disponible 24h/24, multilingue, ancré sur des données fiables, capable de croiser des informations en temps réel. Pas un chatbot à arbre de décision. Un vrai assistant.
Quand on parle d'assistant IA à un client, la première inquiétude c'est : "Et s'il invente des réponses ?"
Un grand modèle de langage laissé à lui-même va produire une réponse plausible même quand il n'a pas la bonne information. Dans un contexte de divertissement, c'est gênant. Dans un contexte où un usager pourrait prendre une mauvaise décision sur la foi d'une réponse erronée comme rater un vol, manquer un rendez-vous médical, déposer un dossier incomplet, cela devient INACCEPTABLE.
Dès le départ, on a posé une règle fondamentale : le LLM n'est pas une source d'information, c'est un moteur de compréhension et de formulation. Il sait interpréter une question complexe, formuler une réponse claire, gérer le multilinguisme, tolérer les fautes de frappe, capable de comprendre et répondre dans toutes les langues sans développement supplémentaire. Mais les données qu'il utilise pour répondre, elles viennent exclusivement des sources que le client nous a désignées comme faisant autorité (même si elles ne sont pas traduites dans la langue de l’usager).
C'est ce principe qui a guidé toute l'architecture.
On construit la solution sur trois couches qui s'articulent ensemble.
La première couche : l’indexation sémantique
Avant même que l'IA entre en jeu, il faut que vos contenus soient lisibles par une machine : pas mot à mot, mais par le sens. On prend l'ensemble des contenus qui font autorité : le site web, les FAQ, les documents PDF, les guides internes… et on les transforme en représentations mathématiques du sens, qu'on appelle des vecteurs. Chaque paragraphe devient un point dans un espace où les idées proches sont physiquement proches. C'est cette carte qui rend tout le reste possible.
La deuxième couche le RAG, ou comment ancrer l'IA sur vos contenus.
Plutôt que de laisser le modèle répondre de mémoire, on lui injecte les bons extraits de vos contenus officiels au moment où il formule sa réponse.
Quand un usager pose une question, elle est vectorisée à son tour, puis comparée à l'ensemble des contenus indexés. En quelques millisecondes, le système identifie les passages les plus proches, pas par correspondance de mots-clés, mais par proximité de sens. Ces passages sont transmis au modèle, qui s'en sert pour construire sa réponse. Il ne peut pas aller au-delà...
Le résultat : l'assistant répond toujours depuis vos sources, jamais depuis des données génériques. Et si vous mettez à jour un tarif ou une réglementation sur votre site, les vecteurs se mettent à jour automatiquement. L'assistant dispose toujours de la version courante.
Une fois que vos contenus sont indexés en base vectorielle, vous pouvez améliorer votre moteur de recherche interne en recherche sémantique. Le plus difficile est déjà fait.
La troisième couche : le MCP, pour les données qui changent à la seconde
Le contenu d'un site web ne suffit pas dès que les données bougent. Un vol peut être retardé. Un parking peut se remplir. Un créneau de rendez-vous peut être pris. Un stock peut être épuisé. Un tarif peut changer.
Pour ces données vivantes, on utilise le Model Context Protocol , MCP, un standard qui permet au modèle d'appeler directement vos API métiers comme des outils, à la demande, selon la question posée. Le modèle décide lui-même quand il a besoin d'une donnée en temps réel et va la chercher. Sans scénario préétabli. Sans configuration au cas par cas.
Quand quelqu'un demande "Mon vol est-il à l'heure ?", l'assistant ne cherche pas dans un contenu statique : il interroge l'API de suivi des vols, récupère le statut en direct, et formule la réponse.
Ce qu'on a trouvé particulièrement intéressant avec le MCP, c'est ce qu'il ouvre au-delà du projet lui-même. En exposant vos API via ce protocole, vos données deviennent accessibles aux assistants IA que vos usagers utilisent déjà au quotidien : ChatGPT, Gemini, Claude en version professionnelle. Vos services deviennent "AI-Ready", visibles là où les gens cherchent maintenant, sans qu'ils aient forcément besoin de naviguer sur votre site.
La quatrième couche : le LLM, choisi selon vos contraintes
Le modèle de langage, on le choisit en fonction du contexte : niveau de performance attendu, contraintes de souveraineté des données, budget. GPT-4o pour les meilleures performances en compréhension complexe, Mistral pour un ancrage européen et une absence de dépendance contractuelle à un éditeur unique, d'autres options selon les cas.
Ce qui compte surtout, c'est qu'on construit une application agnostique : on peut changer de modèle sans réécrire le système. Les LLM évoluent vite. Dans six mois, le meilleur modèle du marché ne sera peut-être plus celui d'aujourd'hui. Vous ne devez pas être captifs de votre premier choix.
On pourrait proposer un déploiement global d'emblée. On ne le fait pas, et ce n'est pas par manque d'ambition.
Un POC sur un périmètre restreint (une thématique, un canal, un sous-ensemble de données), permet de tester la pertinence réelle avant d'engager une infrastructure de production. Les questions que posent vraiment vos usagers ne sont pas toujours celles que vous imaginez. Les volumes d'interactions réels définissent les coûts réels. Le ton juste pour votre image de marque se trouve en testant.
Pendant cette phase, on analyse aussi les statistiques de navigation existantes : quels contenus sont les plus consultés, quelles recherches reviennent le plus souvent. Ce sont eux qu'il faut rendre accessibles en priorité.
On teste ensuite les réponses de l'assistant sur des questions réelles, on vérifie que les données en entrée sont suffisamment complètes, on mesure le taux de questions qui trouvent une réponse satisfaisante. Ce qu'on cherche : que l'assistant ne laisse personne sans réponse utile, ou qu'il sache clairement dire quand il ne sait pas.
C'est aussi pendant le POC qu'on traite les questions RGPD, dès le départ. On intègre un module d'anonymisation qui intercepte les données personnelles (noms, emails, numéros de dossier), tout ce qui peut identifier un usager avant qu'elles n'atteignent le modèle. Ce n'est pas une option qu'on ajoute en fin de projet : c'est une fondation.
La transformation est simple à décrire mais elle change vraiment quelque chose dans l'expérience.
Aujourd'hui, l'usager cherche. Il navigue, reformule, compare des onglets. Il arrive à destination avec la bonne information après un effort qu'il n'aurait pas dû faire.
Demain, il pose sa question. En français, en anglais, avec une faute de frappe, depuis son téléphone, depuis le site, depuis un QR code scanné sur place. Il reçoit une réponse contextualisée, précise, immédiate. Un temps d'attente devient une expérience de service. Une navigation fastidieuse devient une conversation.
Dans les lieux de transit c'est particulièrement visible : le stress est l'ennemi de tout le monde. Mais le principe vaut partout où un usager cherche une information urgente dans un moment chargé : une salle d'attente, un guichet bondé, une démarche administrative sous contrainte de délai. Un usager bien informé au bon moment, c'est moins de charge pour vos équipes, moins d'abandon, et une image de marque qui s'en ressent.
On ne vend pas "un chatbot IA". La différence entre une solution qui tient en production et une démo qui impressionne en réunion ne se joue pas dans le choix du modèle. Elle se joue dans la façon dont on connecte ce modèle à vos données, à vos contraintes, et à vos systèmes.
Ce qu'on maîtrise chez Codéin, c'est cette connexion. L'architecture RAG pour garantir la fiabilité. L'intégration MCP pour les données vivantes. Le choix raisonné du fournisseur selon vos exigences de souveraineté. La construction d'un système que vous pouvez reprendre, auditer, faire évoluer sans nous.
Et derrière l'assistant, on livre aussi un back-office de supervision : les performances, les statistiques d'usage, et, les questions restées sans réponse. Ce sont elles qui vous disent ce que vos usagers cherchent vraiment, ce qui manque dans votre contenu, ce qui mérite d'être traité en priorité.
Ce projet représente bien ce qu'on essaie de faire à chaque fois : partir d'un vrai problème utilisateur, construire une solution fiable, et laisser un système que le client comprend et contrôle.
Vous avez un cas d'usage similaire en tête ou vous explorez comment l'IA peut s'intégrer à vos outils métiers ? On en parle volontiers.


