


NIS 2, Cloud Act, DINUM : on a refondu notre modèle de cahier des charges ...
change de nom...
L’approche « Data as Code » applique les principes du développement logiciel à la gestion des pipelines de données. Elle repose sur des pratiques telles que le versioning, l’automatisation des tests, et la collaboration structurée pour garantir un suivi précis et un haut niveau de qualité. Cependant, cette approche dépend fortement des solutions techniques employées.
Les plateformes no code / low code SaaS (comme Talend Studio, Google Looker, Microsoft PowerBI), limitent souvent la possibilité de versionner efficacement le code. En revanche, des stacks modernes comme Apache Airflow, dbt et Apache Superset sont parfaitement adaptées pour mettre en œuvre une gestion « Data as Code » compatible, permettant de travailler avec des environnements locaux, de structurer des processus de développement agile, et d’industrialiser les déploiements de manière fluide et cohérente.
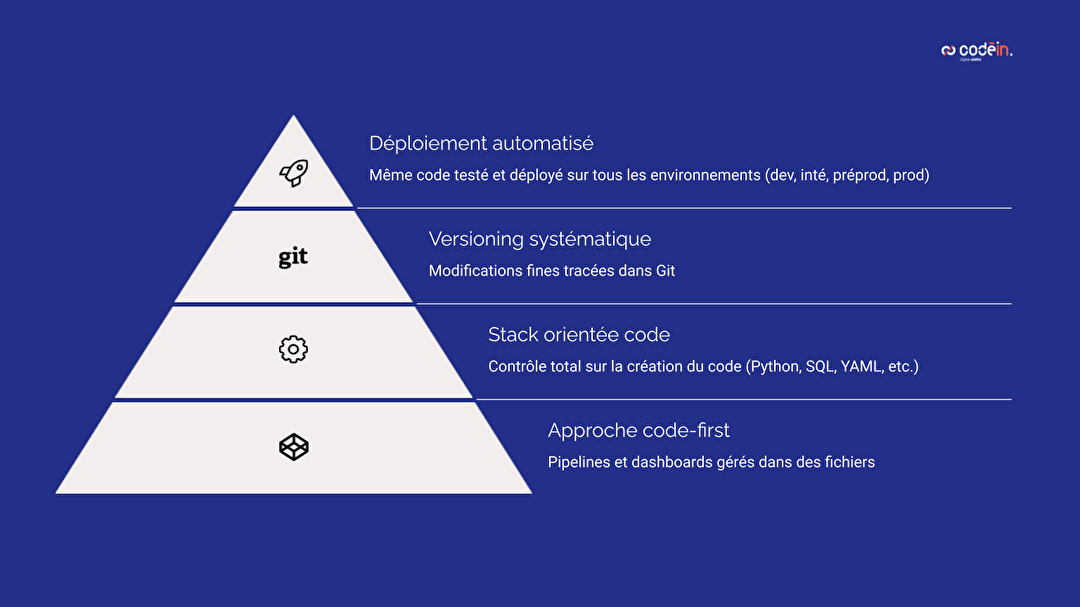
L’approche Data as Code commence par un principe simple : tout est géré par le code. Pipelines, transformations, tests, dashboards ou documentation sont définis dans des fichiers versionnés. Cela permet une centralisation de la logique métier, une meilleure visibilité sur les changements et une base solide pour industrialiser les workflows.
Pour appliquer cette approche, une stack technique orientée code est essentielle. Apache Airflow pour l’orchestration (Python), dbt pour les transformations (SQL/YAML), Apache Superset pour la visualisation des données : chaque outil est pensé pour s’intégrer dans un écosystème de développement moderne. Cette stack donne un contrôle total sur le comportement des pipelines et des dashboards, sans dépendance à des interfaces no-code ou propriétaires.
Tous les fichiers sont tracés dans Git, avec une gestion rigoureuse des branches et des commits. Les évolutions sont regroupées sous forme de features, hotfix, releases ou tags, assurant une traçabilité fine et la possibilité de revenir à une version antérieure en cas de besoin. Cette discipline garantit la stabilité des workflows et facilite le travail en équipe.
Une fois le code validé, il suit un processus de déploiement automatisé sur les différents environnements (développement, intégration, préproduction, production). Les mêmes fichiers sont testés et exécutés partout, réduisant les erreurs manuelles et accélérant la mise en production. Cela permet de fiabiliser le cycle de vie complet des pipelines.
Ce cas pratique illustre comment l’approche Data as Code peut être appliquée pour industrialiser un pipeline de données en s’appuyant sur des outils open source.
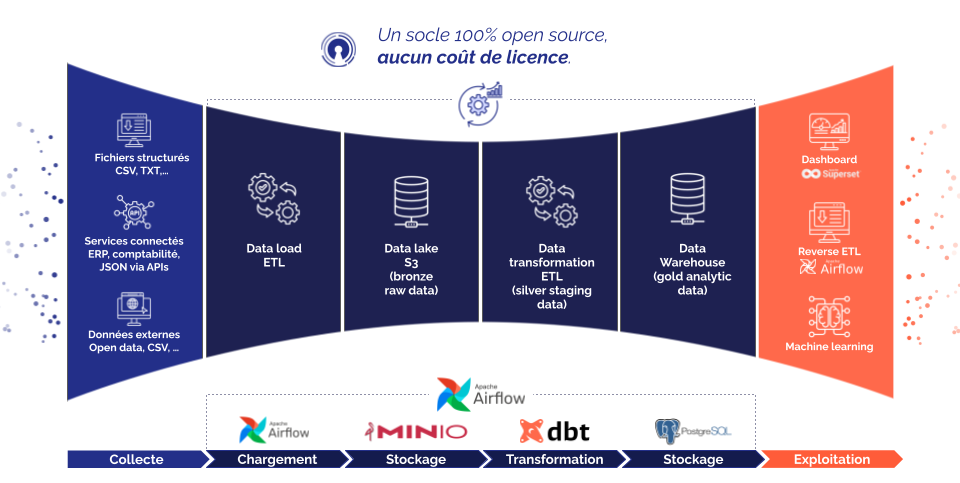
Le projet consiste à collecter des données issues de sources variées, à les centraliser dans un datalake, à les transformer via un outil dédié, puis à les intégrer dans un data warehouse, qui sert ensuite de base pour alimenter des tableaux de bord interactifs.
L’architecture repose sur une stack modulaire et éprouvée :
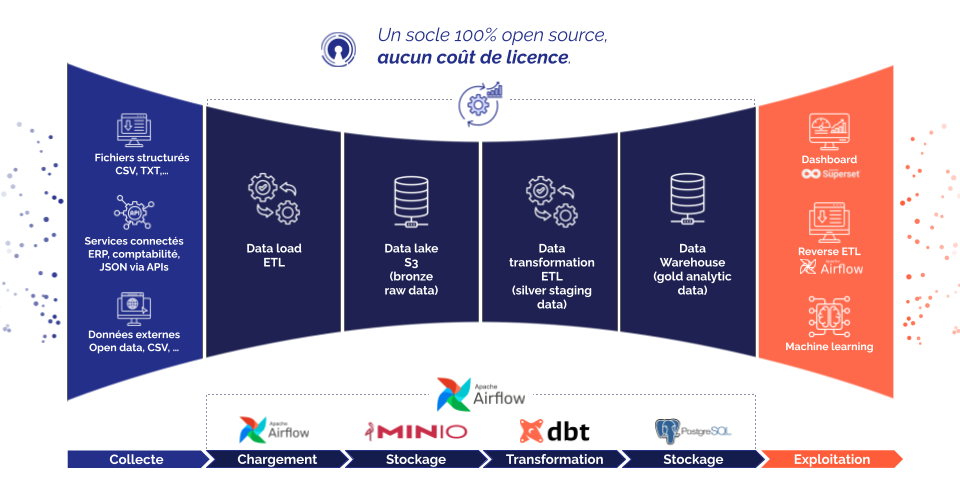
L’objectif de cet articvle n’est pas de détailler chaque étape technique, mais de mettre en lumière les leviers clés de l’industrialisation : gestion du code source, création d’environnements reproductibles, structuration du cycle de développement, et déploiement automatisé.
La première étape du projet est la création d’un dépôt Git, qui centralisera le code et les configurations. Ce dépôt constitue le point de référence unique pour la gestion des versions et la collaboration entre les membres de l’équipe.
Chez Codéin, nous utilisons notre propre serveur GitLab pour héberger les projets de nos clients. Cependant, d’autres solutions comme GitHub, Bitbucket ou tout autre gestionnaire de sources compatible avec Git peuvent être utilisées en fonction des besoins du projet et des préférences de l’équipe. Le choix de la plateforme dépendra notamment des fonctionnalités requises, de la politique de sécurité, et de l’écosystème de l’organisation.
Pour appliquer l’approche "Data as Code", il est essentiel de disposer d’un environnement de développement aussi proche que possible de la production. Grâce à une infrastructure basée sur Docker, tous les services nécessaires au projet — orchestration, transformation, visualisation, stockage et base de données — sont packagés dans un environnement isolé, reproductible et facile à démarrer.
Parmi ces services, on retrouve notamment Apache Airflow pour l’orchestration, dbt pour les transformations, Apache Superset pour la visualisation, PostgreSQL comme base centrale, MinIO pour le stockage objet et Adminer pour la gestion de base. L’ensemble est défini via des fichiers Docker Compose, permettant de construire et synchroniser les containers automatiquement.
Une fois l’environnement lancé, un script automatisé prend en charge la configuration initiale : base de données, DAGs, dashboards, dépendances dbt… L’objectif est clair : permettre à tout développeur d’être opérationnel en quelques minutes, avec un environnement local fidèle à celui de la production.
Le cycle de développement s’appuie sur une organisation simple et structurée, qui combine gestion de projet, bonnes pratiques Git et automatisation. Chaque nouvelle fonctionnalité démarre par la création d’un ticket dans un outil de suivi (comme Redmine), ce qui permet de centraliser les demandes et de planifier les évolutions à venir.
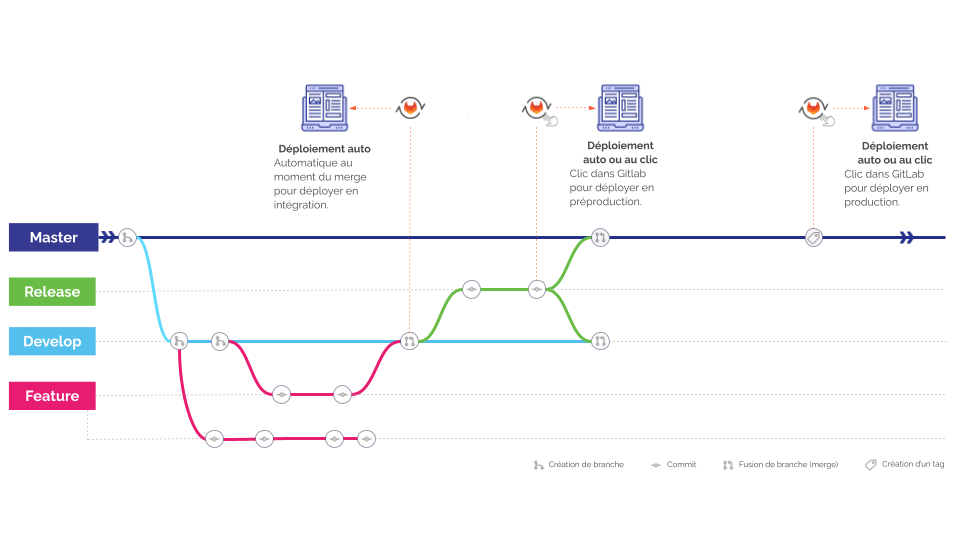
Le développement se fait sur des branches Git dédiées, selon le modèle Gitflow. Cela permet à chaque développeur de travailler de manière isolée, tout en facilitant l’intégration progressive des changements. Une fois les développements terminés, le code est regroupé dans une branche de recette(release), préparée pour être testée puis déployée.
Tout au long du processus, des vérifications automatiques sont déclenchées : analyse de qualité de code, exécution de tests, et vérification du style. Ces étapes garantissent un haut niveau de fiabilité et réduisent les risques d’erreurs.
Avant d’intégrer une fonctionnalité, une revue de code est réalisée par un autre membre de l’équipe. Ce moment d’échange améliore la qualité du code, renforce la cohésion de l’équipe et permet une meilleure diffusion des connaissances.
Enfin, une fois le code validé, il est fusionné dans la branche principale et déployé sur les différents environnements, selon un processus standardisé. Chaque version est identifiée par un tag, ce qui permet de tracer précisément les évolutions et de revenir en arrière si nécessaire.
Cette organisation offre un cadre de travail clair, favorise la collaboration, et sécurise l’ensemble des mises en production.
Le processus de déploiement repose sur un duo éprouvé : Capistrano pour l’exécution et GitLab CI/CD pour l’orchestration. Cette combinaison permet des déploiements automatisés, fiables et sécurisés, tout en offrant souplesse et contrôle.
Capistrano exécute les déploiements en mode offline : le nouveau code n’est mis en ligne qu’après validation complète. En cas d’erreur, la version précédente reste active, garantissant une continuité de service sans interruption. Ce processus inclut l’ensemble des étapes pré et post-déploiement nécessaires pour assurer la mise à niveau de l’application en production, comme la mise à jour des dépendances, les migrations de base de données, ou la vidange du cache.
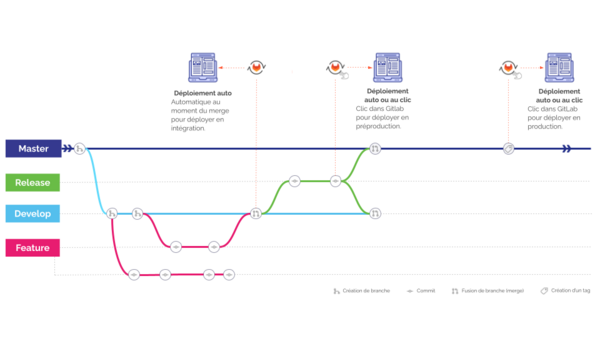
Les déploiements sont orchestrés par GitLab CI/CD, selon des règles définies :
En cas d’échec, Capistrano permet un rollback rapide vers la dernière version stable. La gestion des accès est centralisée dans GitLab, et seuls certains utilisateurs peuvent déclencher un déploiement ou exécuter des migrations. Enfin, seuls la branche principale et les tags validés peuvent être utilisés pour un déploiement en production, assurant un contrôle strict des versions.
En combinant les forces de Capistrano et GitLab CI/CD, ce processus assure des déploiements fiables, industrialisés et conformes aux meilleures pratiques. Chaque étape est conçue pour minimiser les risques tout en garantissant la qualité et la continuité du service.
Exemple de workflow de déploiement avec gitlab CI/CD
| Efficacité | Automatisation des tâches répétitives, réduction des erreurs humaines, accélération des déploiements. |
| Qualité du code | Code versionné, structuré et testé, garantissant la fiabilité des pipelines. |
| Flexibilité | Intégration facile de nouvelles sources de données, d’outils ou de fonctionnalités. |
| Pérennité | Stack open source, sans dépendance à un éditeur propriétaire. |
| Collaboration | Meilleure organisation grâce aux workflows Git, aux revues de code et au versioning. |
| Traçabilité | Suivi clair de toutes les modifications via Git ; meilleure auditabilité. |
| Extensibilité | Architecture modulaire adaptable à différents contextes métiers ou techniques. |
| Volumétrie de données | Environnements locaux parfois insuffisants ; nécessite des stratégies d’échantillonnage ou d’environnement cloud. |
| Données sensibles | L’anonymisation ou le masquage des données complexifie les tests et le débogage. |
| Courbe d’apprentissage | Besoin de formation sur les outils (Docker, Airflow, dbt, Superset, Git, CI/CD, Capistrano…) |
| Coût de maintenance | Les outils open source nécessitent une veille, des mises à jour et du support interne. |
| Débogage technique | Analyse d’erreurs parfois complexe, surtout pour les profils moins techniques. |
| Adoption en interne | Nécessite un accompagnement au changement, notamment pour les profils métiers. |
Cette synthèse met en évidence les atouts majeurs de l’approche "Data as Code", tout en restant réaliste sur les défis techniques et organisationnels qu’elle peut poser.
L’approche Data as Code permet de structurer et d’industrialiser les projets data en s’appuyant sur des outils open source comme Airflow, dbt ou Superset. Elle offre plus de flexibilité, de contrôle et d’indépendance que les solutions propriétaires tout-en-un.
Cette méthode demande un investissement initial, notamment pour la mise en place technique et la montée en compétences. Mais les bénéfices sont rapides : des workflows plus fiables, une meilleure collaboration et une architecture plus évolutive.
Chez Codéin, on vous accompagne pour mettre en place cette approche de façon concrète et adaptée à vos besoins.


