

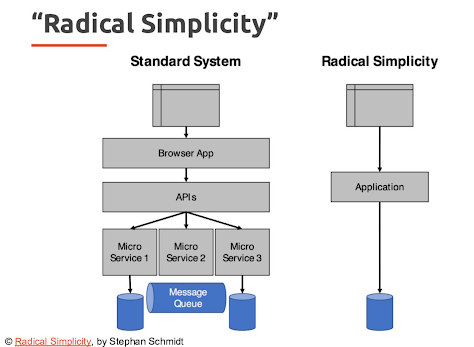



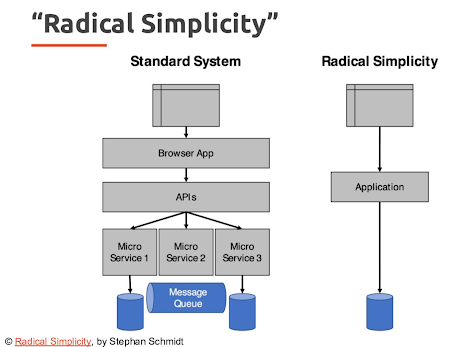
Notre point de vue technique sur la DXP Ibexa
change de nom...

L'agence Codéin est experte en développement d’applications Symfony, nous avons donc naturellement envoyé une délégation à la conférence annuelle de SensioLabs qui a lieu chaque année fin mars à Paris. Aussi, en tant que partenaire de SensioLabs nous avons décidé de sponsoriser cet événement.
Pour rappel, SensioLabs est l’entreprise qui développe le framework libre et open source Symfony. Ses outils sont de grande qualité, ils nous permettent de développer des applications sans coût de licence. Nous pouvons nous appuyer sur la communauté pour obtenir un code en constante amélioration et évolution. Le modèle de l’open source a besoin de contributeurs et de sponsors, Codéin prend sa part et compte bien y contribuer sur le long terme. Symfony le lui rend bien ;-)
Il est important de souligner que la conférence Symfony Live 2024 était avant tout destinée à un public technique et expérimenté, principalement des développeurs. Les sessions étaient riches en contenu technique, ce qui en faisait un événement particulièrement adapté aux professionnels de ce domaine.
Avant de poursuivre, il faut noter que ce compte rendu ne se veut pas exhaustif, mais plutôt une série de notes reflétant les aspects pertinents tels que nous les avons perçus.

Le créateur du framework Symfony a accueilli les participants, remercié les partenaires et nous a présenté la façon dont les repository de Symfony étaient conçus, découpés, gérés.
Le dépôt principal “mono-repo” de Symfony contient des bundles/composants. Pour autant, chaque bundle est lui aussi publié sur son propre repo. Pour cela, git subtree a été utilisé afin que le contexte des mises à jour de chaque bundle “many-repos” soit bien contextualisé dans l’évolution du dépôt principal.
Git subtree est une alternative à submodule. Il permet une collaboration bidirectionnelle entre le dépôt principal et les sous-projets. L’historique de la période avant découpage est lui aussi conservé dans les nouveaux dépôts. Les mises à jour inter dépôts sont possibles.
La présentation est allée jusqu’à montrer les mécanismes utilisés par git pour réaliser ces découpages (méta-données, blob, hash, squash, etc…).
Fabien Potencier propose d’ailleurs un outil qui simplifie l’utilisation de git subtree : splitsh-lite afin de synchroniser automatiquement un référentiel monolithique avec des référentiels autonomes en temps réel.

Voici les slides de Fabien Potencier qui présentent ce sujet : https://speakerdeck.com/fabpot/a-monorepo-vs-manyrepos
Kévin Dunglas est le co-fondateur de Les-Tilleuls.coop, fait partie de la Core team Symfony, a créé API Platform, FrankenPHP et Mercure.
Il nous a présenté des alternatives à la création de Single Page Applications (SPA) en tendant vers une approche simplifiée qui répond souvent aux besoins finaux, sans sortir l’artillerie lourde des framework JS. Et cela peut attirer des développeurs Symfo qui sont moins à l’aise avec ces derniers. Cela peut aussi simplifier la vie de certains projets : moins de compétences requises, moins de composants, etc…
Les SPA sont souvent des applications mono page, les navigateurs chargent toute l’application lors de la première visite, les interactions (données, événements, …) sont ensuite gérées entre API et des composants JS. Pour cela, l’architecture de l’application nécessite beaucoup de composants.
L’approche simplifiée met au placard les frameworks JS, et webpack n’est plus nécessaire. Plus besoin de développer d’API, l’architecture système s’en trouve simplifiée.
Hotwired (Turbo + Stimulus) fournit des possibilités pour faire de l’interaction front sans rechargement de la page, AssetMapper peut gérer les assets. Et en général : plus besoin d’écrire de JS (uniquement twig/symfony/html) ! Les URL peuvent varier. Sans JS l’application est malgré tout servie, Les Turbo-frame permettent d’affiner le chargement de partie de pages avec des préférences de cache différentes.
SymfonyUX (cf plus bas) fournit des packages qui devraient répondre à beaucoup de problématiques dans cette approche (live components, chart.js, notify, autocomplete, …).
Le grand avantage de cette approche est aussi la simplification de la gestion du cache, du SEO.
Cette approche est conseillée dans des projets type CMS, e-commerce, application métier “simple”.
En résumé : ce sont des parties de code HTML générées côté serveur qui sont échangées avec le client. Le DOM est modifié avec un diff en fonction des réponses reçues.
Bien entendu, l’approche plus classique garde aussi ces avantages : quand une API existe ou doit être consommée par plusieurs services, elle a lieu d’être. Les applications plus poussées ne peuvent pas entrer dans cette case.
Ensuite, Kévin nous a rappelé l'intérêt de FrankenPHP, un serveur d’application Symfony tout en un. Il sert l’application php, gère les certificats, supporte HTTP 3, permet de transformer nos applications PHP en binaires, embarque les extensions php classiques, inclut aussi Mercure (pour faire des push) et supporte Prometheus. Les performances seraient au RDV avec le mode worker (on n’a pas testé). Merci pour la contribution !
Voici les slides qu’il met à disposition : https://dunglas.dev/2024/04/front-end-application-development-symfony-styles/
L’objectif de ce talk est de refaire un point sur notre façon de gérer les logs dans le cadre de l’observabilité de nos applications.
Dans les bonnes pratiques recommandées, en voici une sélection :
Voici les slides de cette présentation : https://speakerdeck.com/lyrixx/vos-logs-meritent-mieux-que-la-config-par-defaut
L'intérêt de cette conférence est de présenter les bonnes pratiques dans la création et l’utilisation des rôles et permissions d’une application Symfony.
La notion de rôle doit être associée à une fonction. Par exemple : un lecteur, un administrateur, un modérateur.
La notion de permission correspond à un agrément pour réaliser une action (lecture d’un article, modification d’un utilisateur, suppression, …).
Un rôle est composé de plusieurs permissions.
Les rôles peuvent être organisés en hiérarchie : un utilisateur qui a le rôle administrateur hérite du rôle modérateur.
La méthode hasRole détermine si un utilisateur a un rôle sans tenir compte de la hiérarchie. Il faut donc utiliser la méthode isGranted (méthode héritée du baseController). La hiérarchie est donc parcourue.
Le contrôleur n’est pas censé gérer le contrôle d’accès en comparant l’utilisateur loggé et le contenu en cours d’édition par exemple. A terme, cela peut devenir lourd et difficilement maintenable. Il devrait s’en tenir à l’utilisation d’un isGranted via les attributs.
A partir du moment où des permissions fines sont nécessaires, des stratégies avancées doivent être mises en place. Exemple : un utilisateur ne peut que modifier les articles dont il est l’auteur.
L’utilisation des attributs “IsGranted” est une première solution pour gérer le contrôle d’accès basé sur les attributs “ABAC”. C'est-à-dire que le controller ne va pas regarder le rôle de l’utisateur, mais déléguer la décision d’accès en fonction du contexte fourni dans l’attribut. Ex : l’utilisateur est l’auteur de l’article.
La solution à privilégier est le Voter. C’est une élection où des voters sont appelés pour exprimer leurs votes (abstention, oui, non). Le premier qui dit “oui” ouvre la porte.
Symfony fournit des voters en fonction des rôles : RoleVoter, ExpressionVoter. On peut développer ses voters custom.
Il est aussi possible de créer des PermissionVoter qui sont encore plus précis. A partir de sujets et d’attributs, le voteur peut donner son verdict : access_granted, access_denied.
Voici la documentation Symfony à ce sujet : https://symfony.com/doc/current/security/voters.html
Et les slides de cette session : https://slides.com/chalasr/ne-pas-confondre-role-et-permission
Ce talk nous a présenté des façons d’améliorer la performance de la sérialisation d'objets. La sérialisation consiste à exporter un objet dans un format exploitable et plus petit, dans l’objectif de le transporter, sauvegarder, …
Le composant TypeInfo est mis à disposition de la communauté pour intégrer des métadonnées dans la sérialisation, cela a pour intérêt de mutualiser la sérialisation tout en gardant les données spécifiques.
Les soucis de performance liés à la sérialisation sont souvent causés par la quantité de données stockées en mémoire (gros tableaux), quand on exporte des collections par exemple. Le composant JsonEncoder va encoder “petit à petit” la string. Les bundle AutoMaper et TurboSerializer sont aussi présentés (à titre expérimental à ce stade) pour améliorer significativement les performances.
Voici les slides de la session : https://slides.com/mathiasarlaud/symfony-live-un-serializer-sous-strodes
Simon nous a présenté des outils de l’initiative Symfony UX.
UX Icons : permet d’intégrer des icons SVG dans un catalogue très fourni
Live components : sortis au même moment que les twig component.
Les Twig Component sont constitués d’un template et d’une classe PHP. Ils peuvent s’intégrer avec une syntaxe HTML <twig>. Les développeurs front sont autonomes pour définir les variables nécessaires aux templates.
Les Live Components reprennent ce principe, il suffit de transformer les twig component en utilisant l’attribut “AsLiveComponent” dans sa classe. Le composant devient “live” pour transmettre les changements d'état et créer de l’interaction.
Les live props permettent de lier un attribut à un champ de formulaire par exemple. Une mise à jour côté client est immédiatement mise à jour côté serveur.
Les Live Actions : un bouton dans le composant déclenche une action (via Stimulus) par un appel ajax qui fera appel à une méthode de notre classe PHP.
Les Live Events : le serveur peut écouter des événements, mais le serveur peut aussi envoyer des événements vers le client.
Le Live Loading : pour appeler une fonction toutes les x secondes (pour un live score par exemple), ou pour rendre un composant asynchrone (lazy loading).
Il suffit de require symfony/ux-live-component pour que la couche JS et la configuration soit déployée (grace à Symfony Flex, AssetMapper).
Ils sont très bien intégrés avec : les Symfony Form (entre autres pour la validation),la security, l’AssetMapper, le profiler, les tests.
Les composants peuvent avoir des routes dédiées. Il est aussi possible de modifier en live l’url pour retrouver l’état de la page plus tard (mise en favoris, partage d’URL).
L’approche composant permet d’isoler la fonctionnalité. Les composants peuvent contenir d’autres composants.
Il est possible d’intégrer des live components par petites touches dans nos applications.
Beaucoup de démonstrations sont disponibles ici : https://ux.symfony.com/live-component#demo
Il est possible de ne pas écrire une seule ligne de javascript, ce qui peut être un atout pour certaines équipes.
En termes de performance, il n’y a pas de souci à se faire (cf benchmark).
Il est toujours complexe de développer des applications dépendantes d’API tierce car nous sommes dépendant de leurs accessibilités, et les réponses peuvent varier d’un moment à l’autre ce qui complique les tests.
Une solution pour pallier ces contraintes est de mettre en place des mocks pour obtenir des réponses systématiques et stables. Cependant, leur maintenance peut s’avérer coûteuse. De plus, il est difficile d’anticiper tous les cas de figures de réponses car l’API tierce ne nous appartient pas systématiquement.
Imen Ezzine a présenté une alternative sans mock, tout en restant dans des conditions acceptables.
Des VCR (= Video Cassette Recorder) peuvent être utilisés pour cela : PHP-VCR, Guzzle VCR, PHP-HTTP VCR Plugin.
Ces outils effectuent un premier appel à l’API, enregistrent la réponse, et la fournissent aux appels suivants. Les données sont stockées généralement dans des fichiers, on utilise un client VCR pour faire les appels. Les méthodes classiques (file_get_contents, curl, …) sont automatiquement surchargées pour passer les appels via le VCR.
Voici les slides : https://slides.com/imenezzine/symfony-live-2024
Pendant cette session “libre”, deux sujets sont à retenir.
Une sensibilisation à l’over engineering : créer des applications avec des fonctionnalités plus que nécessaires les rendent inutilement complexes, potentiellement plus lourdes, et augmente le risque de failles de sécurité. Nous sommes souvent tentés d’inclure les dernières bibliothèques, pour utiliser l’un ou l’autre composant pour gagner du temps à court terme.
Ajouter des stack techniques nécessite des équipes à plusieurs profils. L’hétérogénéité des équipes ne pourra peut-être pas être maintenue dans le futur.
Voici d’autres exemples qui devraient nous interroger :
Une présentation du task runner Castor (un phar) : une alternative à nos makefile, écrite en PHP avec autocomplétion dans le terminal et l’IDE. A utiliser dans nos CI, environnements de développement, On peut le compiler pour le déployer facilement. Il est aussi capable de paralléliser des process.
La doc : https://castor.jolicode.com/
Les slides de la présentation de Castor : https://speakerdeck.com/lyrixx/castor-symfony-live-2024-paris
Nicolas Grekas, contributeur principal de Symfony, nous a présenté les nouveautés de Symfony 7.1 après avoir rappelé à l’audience de s’engager “go beyond, composer update and contribute !” et quelques bonnes pratiques.
Stratégies sur les mises à jours :
Quelques nouveautés :
Matheo a fait une démonstration d’une création d’une application qui diffuse des radios sous forme de galerie. Le choix est porté sur une page composée de composants indépendants. Cela permet d’avoir du code réutilisable sur des pages qui nécessitent les mêmes fonctionnalités, sans dupliquer le code back (controller) qui doit envoyer des variables en fonction du contexte. Dans cet exemple, une radio est un composant. Chaque composant a des states (play, pause), des props (nom de la radio, vignette).
Les composants sont des services qui peuvent appeler d’autres services. Le contrôleur est cantonné à traiter la request et la response, sans se soucier des variables nécessaires aux templates.
Il est aussi possible de créer des Anonymous Component qui sont constitués uniquement d’un template sans classe PHP.
SymfonyUI fournit des composants prêt à l’emploi, à l’image d’un design system.
StimulusBundle : intégration de la librairie Stimulus pour revenir aux bases de Javascript, c'est- à dire ajouter du dynamisme à de l’HTML. Il est possible d’écrire les contrôleurs Stimulus pour dynamiser le front.
Les LiveComponents peuvent remplacer les contrôleurs Stimulus quand on a besoin d'interagir avec des données côté serveur.
TurboBundle : pour transformer sa page en SPA. Il observe la page, récupère les événements utilisateurs (click), va faire la requête vers le back, et va merger la réponse reçue avec le dom actuel sans recharger toute la page.
Turbo8 : possibilité de faire des turboframe pour maintenir des parties de la page indépendamment du reste. Par exemple pouvoir continuer à écouter la radio au changement de page, et tout cela sans écrire de javascript.
TurboStream : un controller Symfony va envoyer des request en push client au format stream qui va déclencher des replace en front sur des composants, encore sans javascript.
Les slides : https://github.com/WebMamba/symfony-live-2024
Sofia a fait un talk au sujet des tests.
Un test peu fiable, dit “Flaky” : ce test donne des résultats aléatoires sans modification de code. Cela provoque des incertitudes, frustrations et retarde les livraisons. Cela noie aussi les autres résultats de tests qui devraient nous alerter.
Ex : des tests passés sur la date d’aujourd’hui (qui change tous les jours), des tests dépendants du délai d’attente (qui peut varier), des tests qui dépendent de services tiers dont nous ne maîtrisons pas les retours.
Des outils permettent de détecter ces flaky tests : Allure, CricleCI . Des tableaux de bord permettent de différencier un faux négatif d’un vrai négatif.
Les slides : c'est par ici !

Ce talk a vocation à nous rappeler que nous pouvons transformer nos applications web en Progressive Web App “PWA”.
Une PWA est une application web qui peut être utilisée comme une application native sur les plateformes IOS, Android, etc…
Le PWABundle permet de transformer la web app en PWA. Il permet de mettre en cache des asset afin de pouvoir utiliser l’application hors réseau, de mettre en attente des synchronisations vers des API en fonction du statut de la connexion.
Les PWA sont indépendantes des App Stores. On peut malgré tout les packer pour les livrer dessus, mais attention à la dépendance.
Slides : https://github.com/Spomky/SymfonyLive-2024/blob/main/PWA%20-%20SymfonyLive%202024.pptx
Cette présentation décrit la façon de réaliser une application CQRS/Event Sourcing avec Symfony qui simplifie le process.
CQRS : séparer une application en deux, une structure pour la lecture, une pour l’écriture
ES, Event Sourcing : série d'événements sur lesquels on ne peut pas revenir en arrière pour réécrire l’histoire.
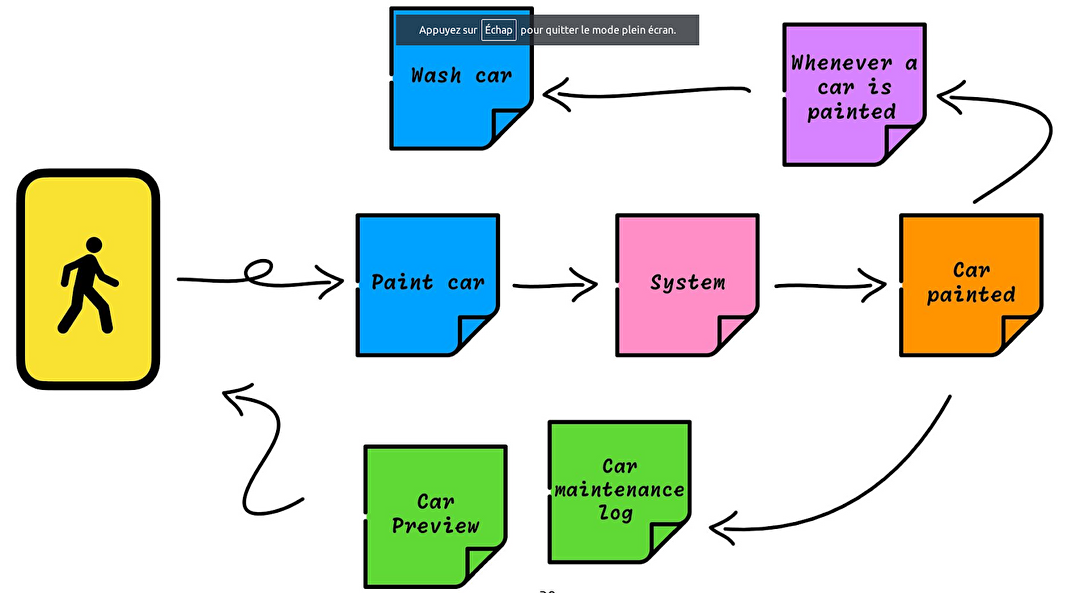
L’idée est de savoir dans quel état est une entité à un moment donné. Par exemple, la couleur de la voiture à une date donnée, et la couleur de la voiture à l’instant T. Pour cela, plutôt que de changer les propriétés de l’objet, on va enregistrer son changement d’état. On enregistre donc des événements.
Les Policy permettent de réagir à des événements : à un changement d’état je réalise cette commande.
L’Aggregate est un cluster d'objets qui garantit la cohérence métier.
L’Entity a un cycle de vie.
Les événements stockés en base stockent les données : identifiant de l’événement, son nom, son aggregate (quel type), la datetime, la donnée, le contexte du changement (quel user par exemple).
Dans cette pratique, nous pouvons rajouter des exceptions métier : on ne peut pas changer de couleur de la voiture plus de deux fois.
Slides : https://speakerdeck.com/jeremyfreeagent/es-avec-symfony-cest-trop-bien
Thomas de PlatformSH et blackfireio nous a parlé d’observabilité. L’observabilité permet de mesurer la performance de l’application, son infrastructure et la contrôler dans la durée.
Voici deux approches complémentaires.
L’observabilité déterministe : plusieurs mesures (temps, cpu, mémoire, etc…) avec mise en évidence des chemins critiques. Blackfire permet de présenter ces mesures de façon habile pour identifier les goulots d’étranglement. Les développeurs peuvent donc s’appliquer à améliorer la performance de certaines briques sans connaître l’intégralité de l’application. Nous pourrons aussi comparer les performances d’une version à l’autre pour valider des améliorations.
Continuous Profiling : mesurer à un instant donné toute l’activité du serveur. En sortie nous n’avons plus une timeline mais le poids des activités à des moments donnés et nous pouvons mesurer leur consommation : ce contrôleur consomme la plus grande partie des ressources car il est souvent utilisé. On ne peut donc pas comparer deux périodes. L’information est fiable si l’utilisation de l’application est représentative.
Voici les slides : https://speakerdeck.com/thomasdiluccio/introduction-to-continuous-profiling
Pour cette dernière présentation, Jérôme de MongoDB nous parle des Attributs qui sont utilisables depuis PHP8. Ces attributs permettent d’avoir un code plus compact et plus efficace.
Les attributs sont optionnels.
Voici quelques attributs qui améliorent et simplifient notre code :
Bonnes pratiques :
Rector est un outil qui va migrer le code pour ne pas avoir à le faire à la main.
Les slides : https://jerome.tamarelle.net/slides/2024-03-29-SymfonyLiveParis2024-Attributs.pdf


