Processing One Billion Rows in PHP
1BRC Challenge
Optimisation du traitement d'un milliard de lignes en PHP
Objectif de la Conférence :
La conférence se penche sur la résolution d'un défi 1BRC, en mettant en lumière diverses techniques pour optimiser le traitement d'un gigantesque fichier de données (composé d'un milliard de lignes) en PHP, un langage souvent critiqué pour ses performances. L'objectif principal est de réduire le temps d'exécution du script en affinant les méthodes de lecture et de traitement des données, démontrant ainsi comment surmonter les limitations de performance de PHP.
Optimisation du traitement d'un milliard de lignes en PHP
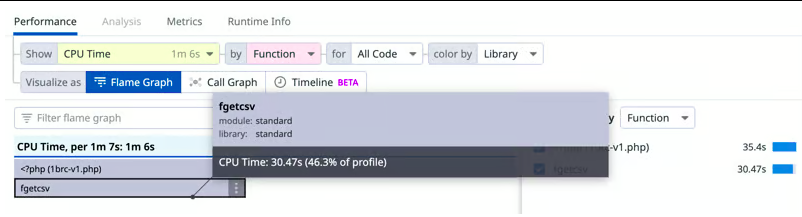
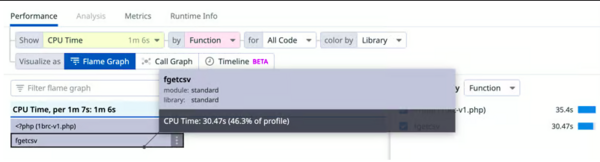
- Utilisation de fgets() au lieu de fgetcsv() :
- Problème : fgetcsv()
est trop lourd pour cette tâche, car il fait beaucoup plus de traitement que nécessaire.
- Solution : Utiliser fgets()
pour lire ligne par ligne et traiter les données manuellement en séparant les champs.
- Optimisation des accès aux tableaux :
- Problème : Accéder directement aux éléments d'un tableau associatif peut être coûteux.
- Solution : Utiliser des références pour éviter de rechercher la clé dans le tableau à chaque accès.
- Minimiser les comparaisons problème :
- Problème : Les comparaisons inutiles dans les boucles peuvent ralentir le traitement.
- Solution : Regrouper les comparaisons pour éviter des calculs redondants (par exemple, utiliser elseif
au lieu de deux if
séparés).
- Cast de type :
- Problème : Le "type juggling" des types peut être coûteux.
- Solution : Ajouter des casts explicites pour éviter le "type juggling" de PHP, ce qui réduit le temps de comparaison.
- Optimisation avec JIT :
- Problème : La compilation Just-In-Time peut améliorer les performances, mais est désactivée par défaut dans certaines configurations PHP.
- Solution : Activer JIT et ajuster les paramètres d’OPCache pour voir des améliorations significatives en performance, puisque OPCache est désactivé en mode CLI.
- Optimisation de la lecture de fichier :
- Problème : Lire des fichiers volumineux peut consommer beaucoup de RAM et ralentir les performances.
- Solution : Ne pas spécifier la longueur maximale lors de l’utilisation de fgets() pour éviter une allocation excessive de mémoire, à moins qu’on connaisse déjà la longueur.
- Parallélisation avec Threads :
- Problème : Le traitement d'un gros fichier en mode séquentiel peut être lent.
- Solution : Utiliser la parallélisation via l'extension parallel pour diviser le fichier en morceaux et traiter chaque morceau en parallèle, réduisant considérablement le temps d'exécution.
Optimisations Additionnelles
- Supprimer isset() : Utiliser des références directes aux éléments du tableau peut économiser des accès supplémentaires.
$station = &$stations[$city];
if ($station !== NULL)
- Éviter les vérifications redondantes : Optimiser les boucles pour éviter des vérifications inutiles des valeurs de retour de fgets().
- Utiliser stream_get_line() : En alternative à fgets() pour une lecture plus efficace en ligne.
Conclusion
Les optimisations apportées permettent de réduire le temps d'exécution du script de 25 minutes à environ 27,7 secondes. Ces améliorations montrent que les performances peuvent être considérablement augmentées en choisissant les bonnes techniques et les bons outils, tout en utilisant PHP, un langage souvent perçu comme moins performant pour les tâches intensives en calcul.
Florian Engelhardt a utilisé un outil puissant développé par Datadog pour mieux profiler le script : DataDog dd-trace-php. Ce profilage de performance inclut des fonctionnalités telles que le suivi de la sécurité des applications (ASM) et le monitoring des performances des applications (APM).
Pour plus de détails sur le profilage des scripts PHP en ligne de commande, consultez la documentation de Datadog.
Pour obtenir une vue d'ensemble plus approfondie du code source de la solution : https://github.com/realFlowControl/1brc