
.png)


NIS 2, Cloud Act, DINUM : on a refondu notre modèle de cahier des charges ...
change de nom...
Dans un contexte où les entreprises doivent traiter des volumes croissants de données provenant de sources multiples, l’industrialisation des pipelines de données est devenue un levier stratégique incontournable. Fini le "bricolage" sur Excel : pour exploiter la valeur de vos données, il faut désormais une synchronisation fluide et automatisée entre vos systèmes.
Chez Codéin, agence web experte en data engineering et en solutions open source, nous accompagnons les entreprises déjà engagées dans leur transformation data et souhaitant industrialiser leurs processus de traitement, synchroniser leurs systèmes existants et améliorer la qualité des données.
L’automatisation des pipelines de données offre plusieurs avantages stratégiques majeurs :
EN BREF : FINI LE "cauchemar d’Excel"
L'automatisation ne sert pas seulement à gagner du temps technique. Elle élimine le risque d'erreur humaine (copier-coller, formules cassées). Le gain business : Vos tableaux de bord sont justes, à jour automatiquement chaque matin, et vous prenez vos décisions sur des chiffres certifiés, pas sur des estimations manuelles.
Pour les entreprises déjà dotées de systèmes hétérogènes (ERP, CRM, bases de données, outils métier…), l’enjeu est souvent de connecter et synchroniser les flux de données pour casser les silos.
Nous concevons chez Codéin des pipelines capables de :
Chez Codéin, nous nous appuyons sur un écosystème open source éprouvé pour construire des pipelines robustes et modulables présentés ci-dessous.
Plateforme de gestion de workflows, Apache Airflow est un outil incontournable pour planifier, surveiller et orchestrer des pipelines complexes.
Points forts :
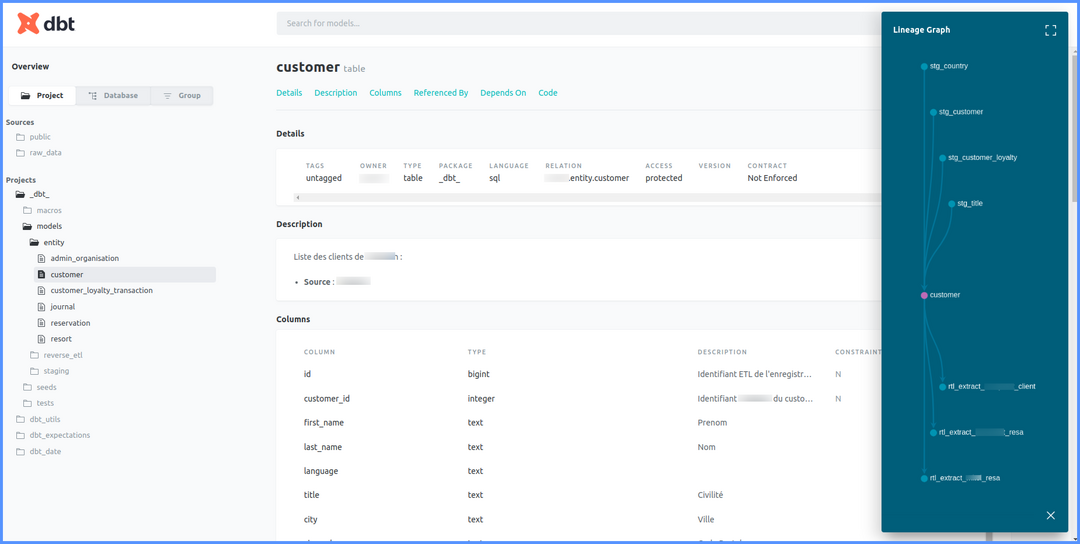
Outil de transformation SQL, dbt simplifie la gestion des transformations de données et leur traçabilité.
Points forts :
Base de données relationnelle open source, PostgreSQL est un choix fiable pour le stockage des données "standard".
Quand aller au-delà ? :Pour des volumes de données massifs, nous utilisons des solutions comme Apache Hadoop et Apache Iceberg, spécialisées dans la gestion de grands lacs de données.
EN BREF : LE CHOIX DE L'INDÉPENDANCE
Nous utilisons des standards Open Source reconnus mondialement (la "Modern Data Stack"). Le gain business : Contrairement aux solutions propriétaires "boîte noire" très coûteuses, vous restez propriétaire de votre code et de vos données. C'est une garantie de pérennité, d'économies sur les licences logicielles, et d'indépendance technologique.
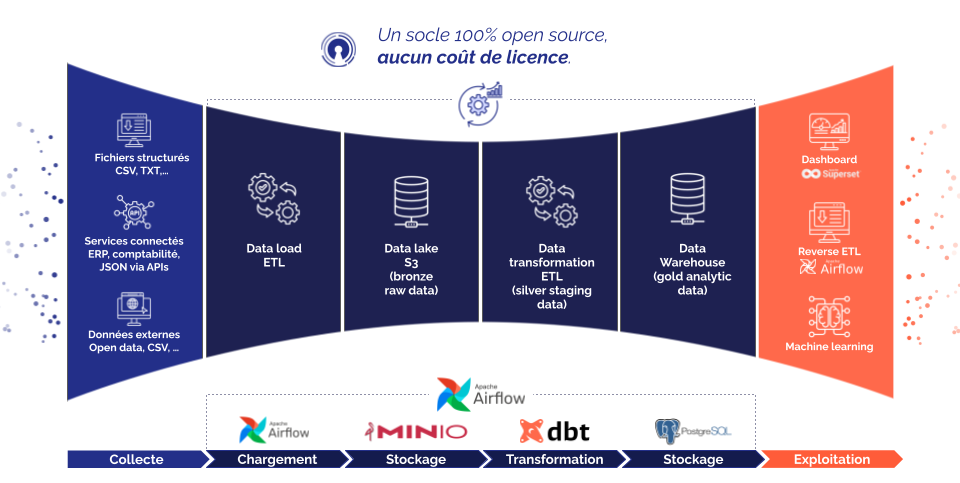
La modélisation en médaillon est une approche structurée pour organiser les données selon trois niveaux de qualité :
.png)
Cette stratégie favorise la clarté, la traçabilité et la réutilisabilité des données. En pratique, cela permet aux entreprises de garantir une meilleure accessibilité des données à chaque étape de leur cycle de vie. Par exemple, les données "Gold" deviennent une source fiable pour les tableaux de bord stratégiques, tandis que les données brutes étagées en Bronze permettent de revenir à l'origine en cas de besoin (audit).
EN BREF : UN FILTRE DE PURETÉ
L'approche "Bronze / Silver / Gold" fonctionne comme un filtre de qualité industrielle. Le gain business : Vos équipes ne perdent plus de temps à "nettoyer" les fichiers. Elles consomment directement la donnée "Gold" pour agir, avec la certitude qu'elle est fiable.
Voici un exemple de pipeline automatisé démontrant un processus complet, allant de la collecte de données issues de plusieurs sources externes à leur consolidation et exploitation.
Le Groupe Sandaya dispose :
Pour ce leader du secteur, l'enjeu n'était pas seulement de collecter la donnée, mais de fiabiliser un écosystème complexe mêlant ERP, PMS et outils de réservation. Grâce à notre architecture Médallion orchestrée par Airflow, nous avons déployé une infrastructure capable d'absorber une charge massive et de garantir la performance :
| Complexité maîtrisée | 35 Sources de données synchronisées chaque jour |
| Temps réel | 3 000 Appels API exécutés quotidiennement |
| Interopérabilité | 10 Composants SI connectés pour un flux unifié |
| Volume et performance | +50 Millions de lignes transformées chaque année |
Objectif du pipeline
Ce pipeline vise à extraire, traiter, filtrer et consolider des données pour :
Illustration du pipeline
Le schéma ci-dessous décrit les différentes étapes et interactions de ce pipeline de données, depuis l’ingestion des informations jusqu’à leur exploitation finale.
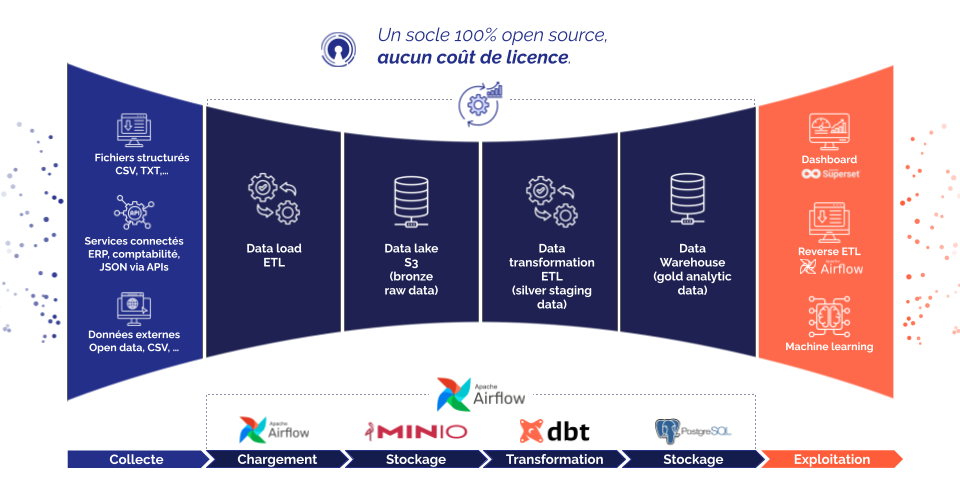
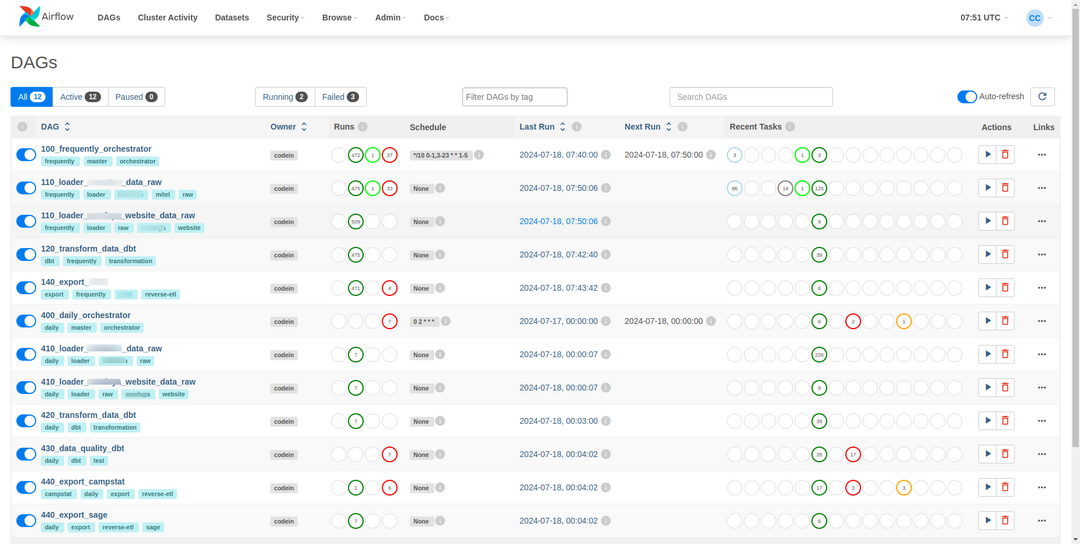
Orchestration par Airflow
Airflow intervient comme un chef d’orchestre. Il organise et planifie un ensemble de tâches dans des workflows appelés DAGs (Directed Acyclic Graphs).
La collecte est comparée à l’extraction de pétrole brut. Trois sources sont mobilisées :
Une fois collectées, les données brutes sont stockées sans altération. Ce stockage brut est crucial pour tracer les transformations (en cas d'erreur) et conserver un historique complet.
C'est également Airflow qui dépose les données sur le S3 et dans la base de données, via des tâches et des opérateurs associés.
En complément, les données sont également persistées dans une base de données PostgreSQL, dans un schéma "raw", pour une manipulation plus aisée dans les étapes suivantes. À ce stade, nous alimentons les données "bronze" de notre architecture en médaillon.
Cette étape correspond au raffinage via dbt.
Les données raffinées sont prêtes à l'emploi :
EN BREF : SÉCURITÉ ET CONTINUITÉ
Le "Data as Code" applique la rigueur du développement logiciel à vos données. Le gain business : Si une mise à jour fait planter un rapport, nous pouvons "rembobiner" instantanément à la version précédente. C'est l'assurance d'une continuité de service pour vos équipes opérationnelles.
Automatiser les pipelines de données et synchroniser les systèmes existants va bien au-delà de la simple productivité technique. Cela permet une gestion robuste, transparente et optimisée de votre capital "Data". Grâce à des outils comme Apache Airflow, dbt et PostgreSQL, combinés à une approche "Data as Code", Codéin aide ses clients à transformer leurs données en actifs stratégiques.


