

.png)
OpenAI a bâti Apps SDK sur MCP. 97 M téléchargements SDK par mois fin 2025. ...
change de nom...
Une donnée de mauvaise qualité peut entraîner des erreurs coûteuses. Imaginez des décisions prises sur des rapports contenant des doublons, des valeurs manquantes ou des données obsolètes. Pour éviter cela, il est nécessaire de mettre en place des tests et des contraintes sur vos pipelines de données. Ces tests permettent non seulement d'identifier les problèmes, mais aussi d'améliorer la confiance dans vos analyses et vos outils de reporting.
dbt, outil open source très populaire dans l'écosystème de la donnée, permet de transformer et de modéliser les données tout en intégrant facilement des contrôles de qualité. Voyons ensemble comment l'utiliser.
Pour suivre cet exemple, vous aurez besoin des éléments suivants :
Les fichiers sources du projet et les configurations des conteneurs sont disponibles sur le GitHub de Codéin : https://github.com/codein-Labs/data-quality-dbt
Cloner le projet
Commencez par récupérer le projet depuis GitHub en utilisant la commande suivante :
```bash
$ git clone https://github.com/Codein-Labs/data-quality-dbt.git
$ cd data-quality-dbt
Démarrer l’environnement Docker
Lancez les conteneurs Docker avec la commande suivante :
```bash
$ docker-compose up --build -d
Ce que vous obtenez à ce stade
Une fois les conteneurs démarrés, vous disposez de :
Note : Pour exécuter les commandes dbt mentionnées dans cet article, vous devrez accéder au conteneur dbt.
```bash
$ docker exec -it dbt_container /bin/bash
```bash
$ dbt list
La base de données est initialement vide. Pour y injecter des données, nous utilisons la fonctionnalité seeds de dbt. Ces données proviennent de fichiers CSV qui représentent des données brutes, simulant un chargement via un ETL (comme Apache Airflow, par exemple). Ces fichiers sont chargés dans le schéma raw (données brutes) de notre base de données.
Les fichiers à charger sont les suivants :
Étapes pour charger les données :
Placez les fichiers customer.csv, order.csv, product.csv et invoice.csv dans le répertoire seeds / du projet.
2. Configurez le schéma des seeds
Assurez-vous que le fichier dbt_project.yml est configuré pour le schéma des seeds.
Voici un exemple de configuration :
```yaml
# Configuration des seeds
seeds:
schema: raw
3. Lancez la commande de chargement
Exécutez la commande suivante pour charger les données dans la base :
```bash
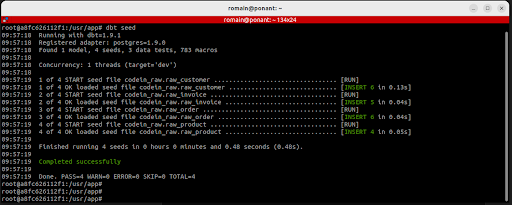
$ dbt seed
Résultat attendu :
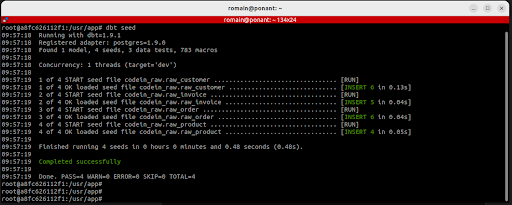
Une fois cette commande exécutée, les données des fichiers CSV seront chargées dans le schéma codein_raw de votre base PostgreSQL. Vous pouvez les explorer directement via Adminer ou en utilisant des requêtes SQL.
Tout est maintenant en place pour commencer à tester la qualité des données.
Créez un fichier SQL models/analytics/customer.sql pour structurer les données des clients :
```sql
-- models/analytics/customers.sql
SELECT
id,
first_name,
last_name,
email,
phone,
date_of_birth
FROM {{ref('raw_customer')}}
Créez un fichier SQL models/analytics/order.sql pour structurer les données des commandes :
```sql
-- models/analytics/orders.sql
SELECT
id,
customer_id,
product_id,
order_date,
amount
FROM {{ref('raw_order')}}
Note :
Ces deux modèles seront générés par dbt à partir des données brutes chargées lors de l'étape précédente. dbt utilise le moteur de templates Jinja pour établir les références entre les différents modèles. Par exemple, la référence {{ ref('raw_order') }} pointe vers les données chargées à l'étape précédente.
Dans ce contexte, les modèles order et customer sont construits à partir des tables raw_order et raw_customer . Cela signifie qu’ils héritent directement de ces tables brutes. Ce concept est connu sous le nom de lineage de données, qui permet de suivre les dépendances et transformations appliquées tout au long du pipeline de données.
Les tests de qualité dans dbt sont définis dans des fichiers YAML associés aux modèles. Ils permettent de vérifier l'intégrité des données selon des règles spécifiques.
Pour le modèle customers, nous allons vérifier :
Fichier YAML associé : tests/customer.yml
```yaml
# tests/customer.yml
version: 2
models:
- name: customer
description: "Modèle pour valider les données des clients"
columns:
- name: id
tests:
- unique:
name: test_id_unique
- not_null:
name: test_id_not_null
- name: email
tests:
- not_null:
name: test_email_not_null
- unique:
name: test_email_unique
- dbt_utils.expression_is_true:
name: test_valid_email_format
expression: "~* '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$'"
- name: phone
tests:
- not_null:
name: test_phone_not_null
- name: date_of_birth
tests:
- dbt_utils.expression_is_true:
name: test_valid_date_of_birth
expression: " <= NOW()"
Pour le modèle orders , nous allons vérifier :
Fichier YAML associé : tests/orders.yml
```yaml
# tests/order.yml
version: 2
models:
- name: order
description: "Modèle pour valider les données des commandes"
columns:
- name: id
tests:
- unique:
name: test_unique_id
- not_null:
name: test_not_null_id
- name: amount
tests:
- dbt_utils.expression_is_true:
name: test_positive_amount
expression: " > 0"
- name: customer_id
tests:
- unique:
name: test_customer_id_unique
- not_null:
name: test_customer_id_not_null
- relationships:
name: test_customer_id_relationship
to: ref('customer')
field: id
- name: product_id
tests:
- unique:
name: test_product_id_unique
- not_null:
name: test_product_id_not_null
- relationships:
name: test_product_relationship
to: ref('product')
field: id
- name: order_date
tests:
- not_null:
name: test_order_date_not_null
Note :
Avant d’exécuter les tests, il faut construire le modèle, utilisez la commande suivante :
```bash
$ dbt run
Exécutez ensuite les tests avec la commande suivante :
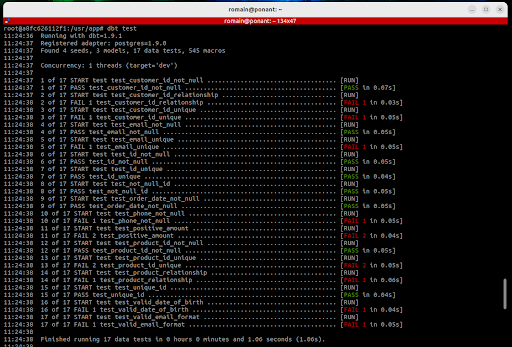
```bash
$ dbt test
Résultat attendu :
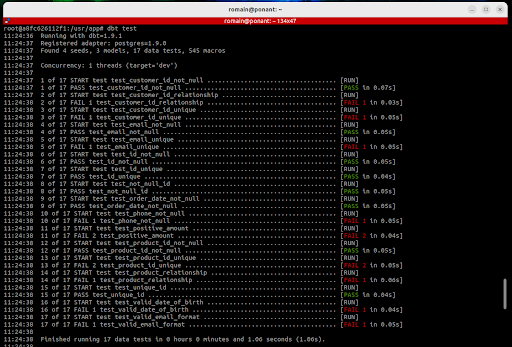
Les résultats des tests s'affichent directement dans la console, ce qui est déjà très utile. Cependant, il est possible d'aller plus loin en enregistrant ces résultats dans un schéma dédié, comme data_quality , au sein de votre base PostgreSQL.
Cette approche permet de centraliser les résultats et de les utiliser pour des analyses ultérieures.
Pour activer cette fonctionnalité, ajoutez la configuration suivante dans votre fichier dbt_project.yml
:
```yaml
# Configuration des tests
data_tests:
+store_failures: true
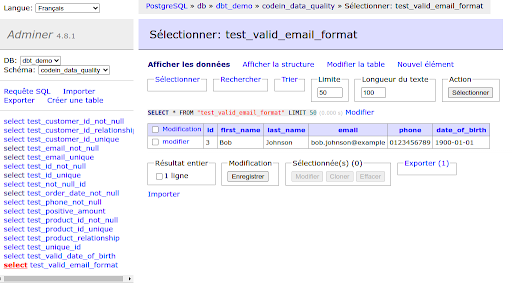
+schema: data_qualityAvec cette configuration, chaque test génère une table spécifique contenant les détails des éventuels échecs.
Cela est particulièrement utile pour le suivi des anomalies. En effectuant un simple count sur ces tables, il est facile d’identifier les tests ayant échoué. De plus, leur contenu permet de localiser précisément les enregistrements concernés, facilitant ainsi la correction.
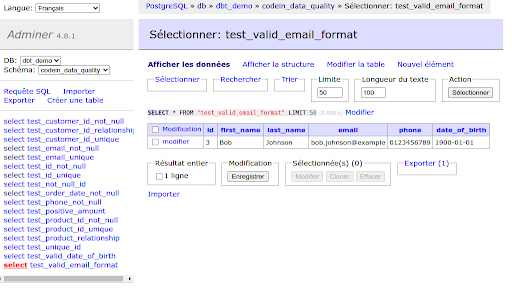
Par exemple, si un test de validation du format d’email échoue, la table associée pourrait indiquer que certains emails manquent de suffixes comme .com ou .fr.
Grâce à cette information, vous pouvez alerter l’administrateur du système CRM et demander une correction des enregistrements concernés. Cette approche contribue à améliorer la qualité globale des données de manière proactive.
Une fois les résultats des tests disponibles dans le schéma data_quality, vous pouvez les intégrer à des outils de BI comme Apache Superset. Cela permet de visualiser rapidement l’état de la qualité de vos données.
Exemple d’utilisation :
La gestion de la qualité des données est un enjeu crucial pour les entreprises, et dbt offre une solution simple et puissante pour répondre à ce besoin.
Grâce à ses fonctionnalités de transformation, de validation et de suivi, dbt permet de garantir l'intégrité des données tout en offrant une grande flexibilité pour répondre aux cas d'usage spécifiques.
En quelques étapes, nous avons vu comment configurer des tests, exécuter des validations, et même centraliser les résultats pour un suivi facilité. Associé à des outils open source comme PostgreSQL et Apache Superset, dbt devient un allié incontournable pour des pipelines de données robustes et fiables.
Avec dbt, vous avez tout ce qu'il faut pour intégrer la qualité des données au cœur de vos processus, et ainsi maximiser la valeur de vos analyses et décisions stratégiques. C'est le moment d'agir pour garantir une donnée fiable et exploitable !


